Jul 16, 2026
•
6 minutes read
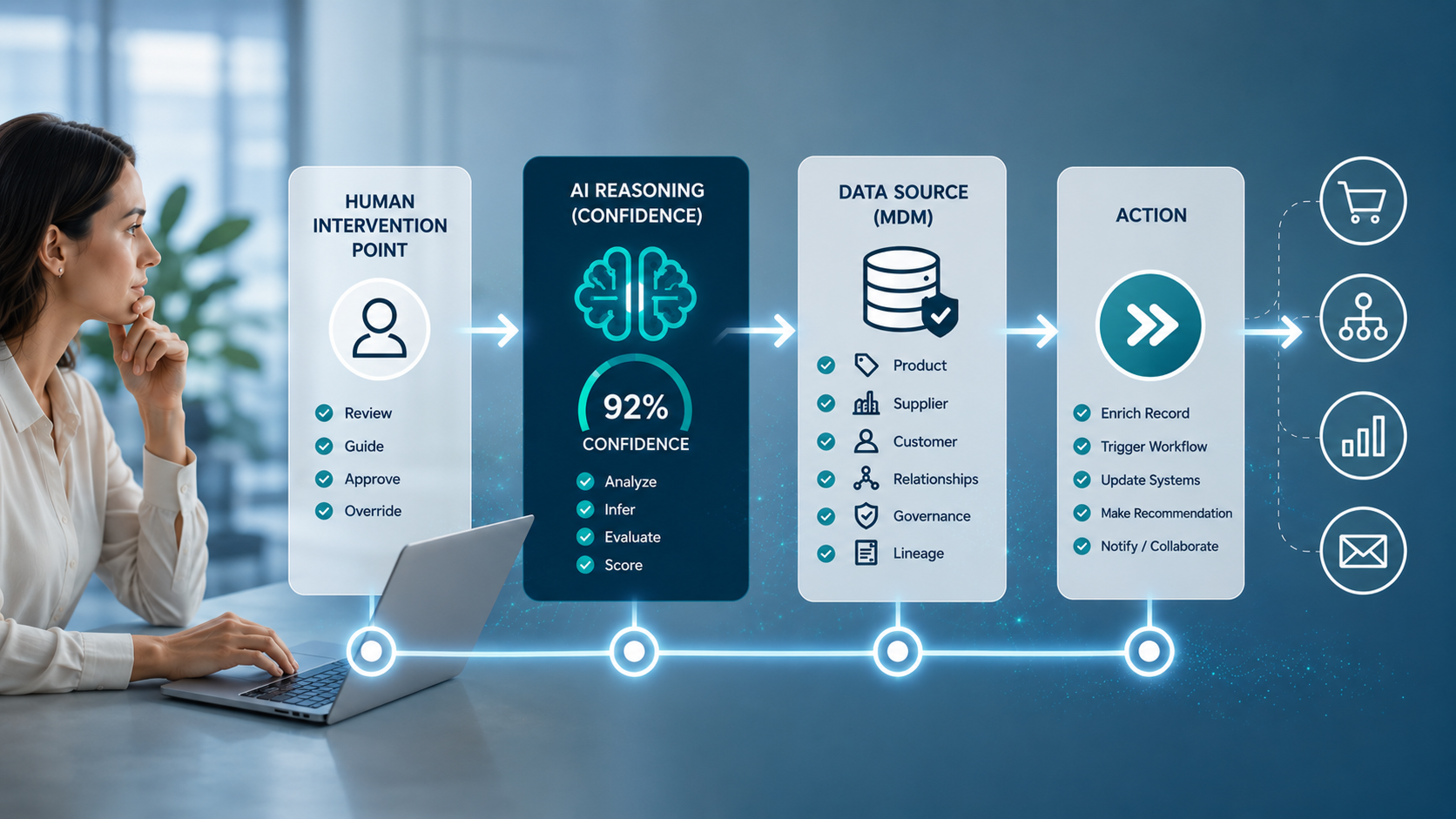
Agentic commerce is moving fast. AI agents can already interpret intent, compare products, and assemble decision-ready recommendations in seconds. What used to take dozens of clicks and multiple sessions can now happen inside a single conversation....
Read the full story →
Discover the newest articles
Trending now

Stibo Systems
Jul 9, 2026
•
5 minutes read


Alison Bruford
Jun 19, 2026
•
4 minutes read