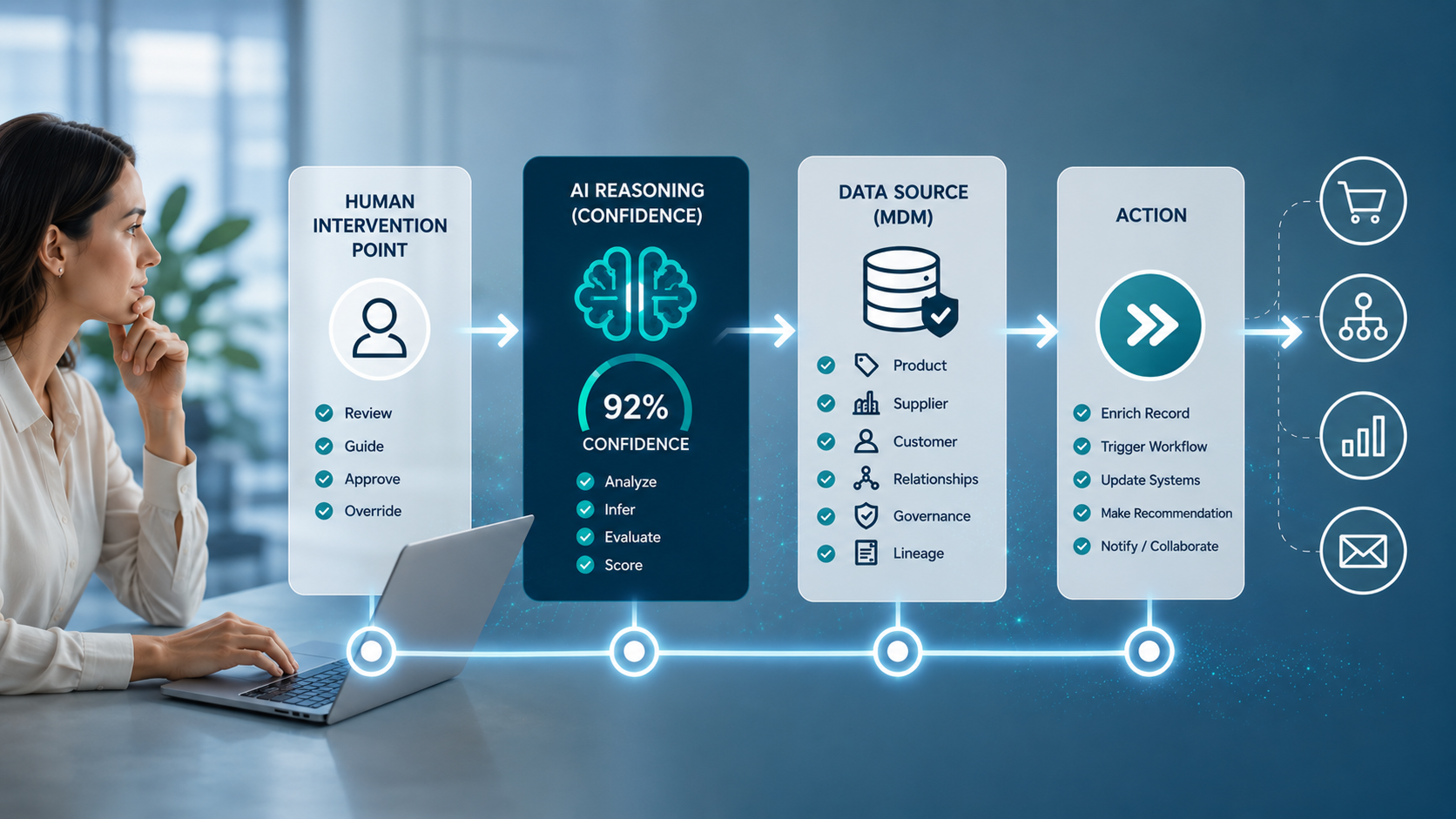
Synthetic data is test data that makes business operations run smoothly; if they are automated with AI or machine learning (ML), master data management is critical to be sure decisions are unbiased.
Data generates data which in turn generates more data. How do we know if what is being produced is fit for purpose? What if a bot, designed to help us to make an informed investment decision or simply provide the best answer to our customer services question, gets it wrong?
Obviously, testing all different corners of solution sets is important. As AI takes a more dominant role in automating decision processes, it is essential to make sure MLOps (maching learning operations), enabled by master data management, are working from high-quality data that is explainable (XAI), trustworthy and free from bias.

Before data becomes operational, it often needs to be organized into data sets to support different types of testing and modelling requirements to see how applications, analytical models and AI-based processes will perform against these real-world/representative/experimental data sets. This is where you need synthetic data.
What is synthetic data and why is it increasingly important?
Synthetic data is generated algorithmically to compensate for real-world data. It supports requirements where real operational data may be insufficient. In many cases, synthetic data derives much of its content from production data; and synthetic data will often be true to the statistical nature of the source data without being an exact copy. Over and above representative real-world data, synthetic data may also include data sets that drive “paths” to test expectations on system behavior under certain conditions and facilitate predictive analytics.
Obviously, synthetic data needs to equal the same level of trust as operational data to be able to deliver useful results. Synthetic data must also be explainable and free from bias for use with AI applications. For that reason, it is crucial first to get the operational, or production data right to provide the starting point for synthetic data generation. It is also important to ensure that use cases not normally found in production data can be assembled and organized. To this end, master data management can help.
What is master data management?
When we think of master data we think mostly of operational data:
- Customer master data used to support sales and service operations
- Product master data collected from suppliers in procurement processes
- Asset master data needed to model essential operational infrastructure
Master data management is a key enabler for providing a single, trusted view of business-critical information, such as customer data. Having trusted master data can help you reduce the costs of application integration, improve customer experiences and yield actionable insight from analytics.
At the crux of making master data both trustworthy and insightful is having a transparent view of it. Transparency originates from the meaning, purpose and governance policy defining the data.
Master data management defines and implements governance policies to certify that important qualities of master data - including origin, accuracy, coherence, accessibility, security, auditability and ethics - are under supervision and measured against business objectives.
Master data management can help you govern your data sets to ensure a more reliable and complete representation of it when generated as synthetic data sets. Good synthetic data sets improve the ability of data science projects to yield better outcomes for forecasting and machine learning.
Synthetic data in AI and machine learning
Synthetic data management is a foundational requirement for AI and machine learning. ML models need to be trained; to do that, they need data. Synthetic data can provide the needed quantities and use cases for ML. Master data management helps support non-bias, and in turn, trusted results, by providing good data to explainable AI verification.
Use of synthetic data in retail
Let’s imagine the launch of a new product. What effect will its placement have on its sales? Which customer segments are more likely to purchase it?
Testing product introduction from a data science perspective, requires access to good, representative data en masse. And this will start with including existing customer and product data. The accuracy and visibility of this data is key to measure and remediate prior to any analytics. This is where master data management can help.
The master data management supports and secures the proper implementation of a policy for customer data, including accountabilities and criteria for completeness and quality. The retailer does not necessarily need a full 360° view of the customer but simply a view that is fit for the specific purpose: creating the synthetic data sets that corroborate a forecasting of the sales potential of the new product.
Should the real-world data lack in richness and volume to support generating data that tests more corners and decision paths, master data management can help by managing anonymous customer data sets that have higher quality.
Having aligned the data rules in the master data management with the goals of the data science or ML project, the retailer is now able to develop appropriate synthetic data sets for subsequent predictive analytics.
AI/ML is becoming a ubiquitous part of the customer experience in helping consumers make informed choices. For example, should the consumer create a collection of viewed products, then the ML algorithms can look at the product’s attributes to propose complementary products and services based on the consumer’s behavioral pattern.
Use of synthetic data in financial services
The financial services sector has a significant number of key synthetic data management use cases. For example, banking or insurance data can contain some very sensitive personally identifiable attributes. But at the same time, financial services companies need to share information with business partners and regulators. Generating synthetic data sets can help remove personal information, also known as data masking, while preserving the essence of the complex data relationships within. In training a fraud algorithm, you don’t really need to have the name of the person involved. You will, however, need to recognize a statistical pattern that represents a suspicious activity.
When analyzing historical trends, the generation of synthetic data sets that represent both actual events and the what-if scenarios is needed if the mistakes of the past are to be avoided. When looking at the future, data sets need to be created that reflect the movement from current to future trends – crucial when imagining your next product or service.
GARTNER REPORT
How Financial Services Institutions Deliver a Better CX

Master data management brings governance to synthetic data to make outcomes explainable
Master data management ensures original production data sets are able to yield representative and helpful synthetic data sets. In some cases, master data management may be needed to manage some elements of those synthetic data sets so they can be curated for machine learning. While techniques such as data masking and synthetic data production (plenty of tools exist to do this) may be used to transform individual attributes, the ability to ensure an honest representation of the original sources can benefit from the data governance policies master data management applies.
Master data management improves the pertinence and explainability of synthetic data by implementing a process to ensure the curation of the originating or synthetic information is representative, coherent, of high quality and insightful. This in turn will make AI more explainable, induce less bias and produce more trustworthy results.
WHITE PAPER
Advance Your AI Agenda with Master Data Management