How to improve the value of master data management through a data lake
This blog post discusses the definition and benefits of a data lake, the difference between a data lake and a data warehouse and how to get started building a data lake.
What is a data lake?
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. The data can then be stored in its raw format and can be processed, analyzed and used for business intelligence and other purposes later on. Data lakes use a flat architecture, where data is stored in its native format without the need for a predefined schema, enabling users to store and process data in a more flexible and cost-effective way.

What are the benefits of a data lake?
Data lakes offer several benefits, including:
1. Scalability
Data lakes can handle large volumes of structured and unstructured data, making them ideal for organizations that need to store and process data at scale.
2. Cost-effectiveness
Data lakes can be less expensive to implement and maintain than traditional data warehouses as they do not require a predefined schema and do not need to be optimized for specific queries.
3. Flexibility
Data lakes allow organizations to store data in its raw format, which makes it possible to add new types of data without having to change the underlying architecture.
4. Accessibility
Data lakes provide a centralized repository for all data, making it easier for different teams and departments to access and analyze the data they need.
5. Time-to-value
Data lakes allow organizations to quickly and easily analyze new data sources, which can help speed up the time it takes to get insights from that data.
6. Advanced analytics
Data lake provide a platform for the wide variety of analytics and machine learning use cases, by providing a single source of truth for data science, business intelligence and data discovery.
What is a data lake vs. data warehouse?
A data lake and a data warehouse are both used for storing and managing large amounts of data, but they have some key differences:
-
Data structure
A data warehouse is designed to handle structured data, while a data lake can store both structured and unstructured data.
-
Schema
In a data warehouse, data is stored in a specific schema and all data must conform to this schema before it can be stored. In a data lake, data is stored in its raw format without the need for a predefined schema.
-
Data processing
A data warehouse is optimized for specific queries and reports, while a data lake is designed to handle a wide variety of data processing needs, including batch, real-time and advanced analytics.
-
Data governance
Data warehouses often have strict data governance rules in place, while data lakes tend to have more flexible governance policies.
-
Accessibility
Data warehouses are typically used by a specific department or team, while data lakes are intended to be accessed by multiple teams and departments within an organization.
-
Cost
Data warehouse solutions are often more expensive to implement and maintain than data lakes due to their specific requirements and optimization for certain queries.
In summary, a data warehouse is more like a relational database, where the data is structured and optimized for specific queries and reporting. On the other hand, a data lake is more like, well a big lake of data, where data is stored in its raw format, providing flexibility for storing and processing data at scale and for a wide variety of use cases.
How to get started building a data lake? A step by step guide
Building a data lake can be a complex process, but here is a general overview of the eight steps you can take:
Step 1: Choose a data lake architecture
There are several different data lake architectures to choose from such as Hadoop-based, cloud-based or a hybrid of the two. Each has its own advantages and disadvantages and therefore, it is important to choose the one that best fits your organization's needs.
Step 2: Select a data lake platform
Select a platform that will provide the necessary storage, compute and data management capabilities to build your data lake.
Step 3: Collect and store the data
Collect and store the data in the data lake. This could include data from internal systems, external sources or IoT devices.
Step 4: Define data governance policies
Define the data governance policies for the data lake, including data access, data lineage and data retention. This will ensure that data is used in compliance with industry regulations and that sensitive data is protected.
Step 5: Prepare the data
Prepare the data for analysis by cleaning, transforming and enriching it. This could include tasks such as removing duplicates, normalizing data or adding metadata.
Step 6: Set up data processing
Set up data processing workflows and pipelines to transform and move data from the data lake to other systems such as data warehouses or data marts for analysis and reporting.
Step 7: Implement security
Implement security measures to protect the data lake such as encryption, access controls and network security.
Step 8: Monitor and optimize
Monitor the performance of the data lake and make adjustments as needed to optimize it. This could include scaling up resources, fine-tuning data governance policies or adding new data sources.
It is important to note that building a data lake is not a one-time task but it is an ongoing process. Therefore, it is also important to continuously monitor, optimize and maintain the data lake to ensure it is always up-to-date and providing valuable insights.
EXECUTIVE BRIEF
How to Develop Clear Data Governance Policies and Processes

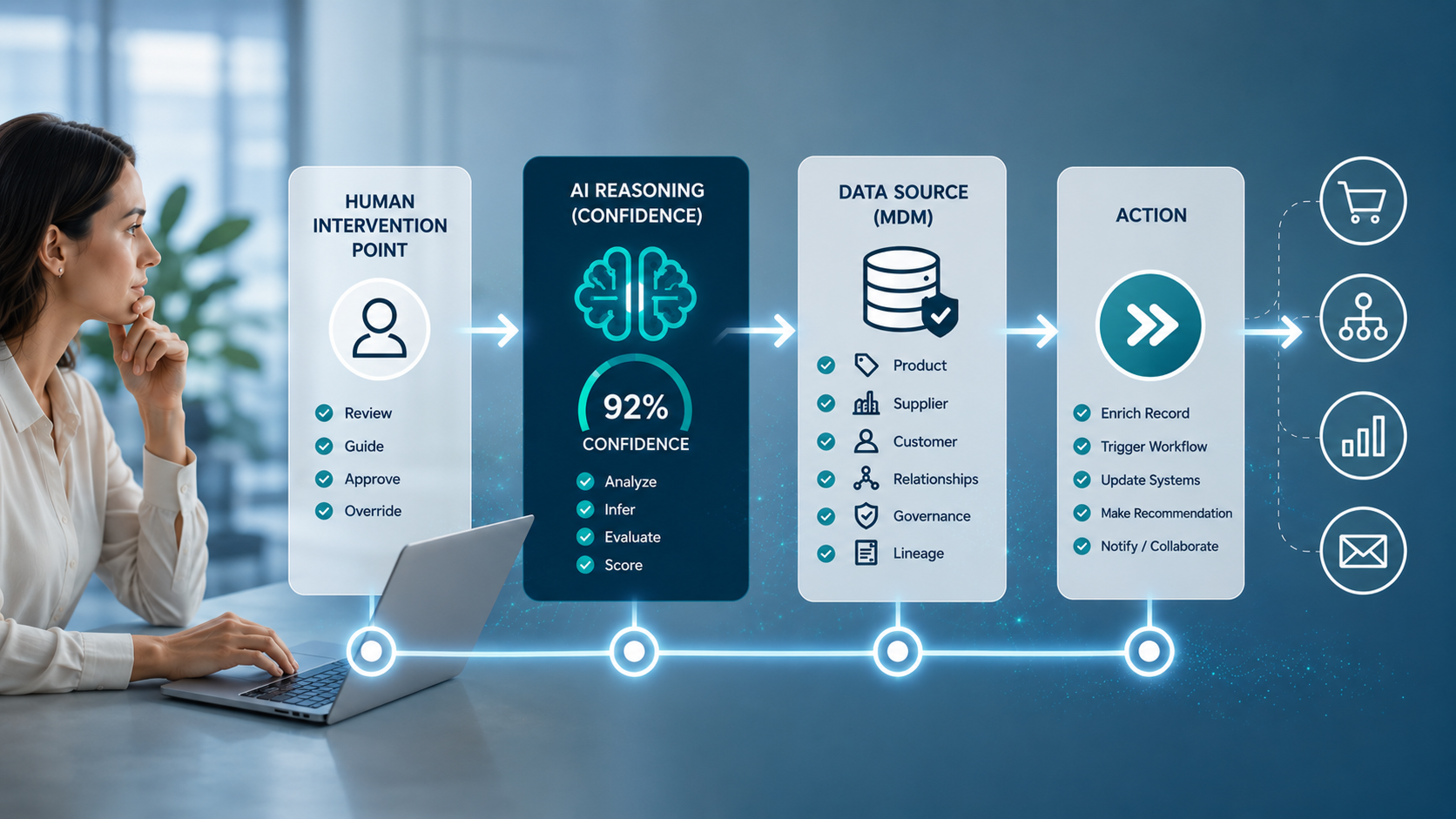
Data lakes and master data management
Master data management and data lakes are both important tools for managing and analyzing large amounts of data, but they serve different purposes.
Master data management is a process of identifying, defining and maintaining a single, accurate and consistent version of important data elements, such as customer and product data, across an organization. It is used to ensure data consistency, data accuracy and completeness and to improve data governance. Master data management solutions often include tools for data profiling, data quality, data matching, data merging and data survivorship.
A data lake, on the other hand, is a centralized repository that allows you to store all your structured and unstructured data at any scale. Data lakes use a flat architecture, where data is stored in its native format without the need for a predefined schema, enabling users to store and process data in a more flexible and cost-effective way.
While master data management and data lakes serve different purposes, they can be used together to provide a complete data management solution. Master data management can be used to clean and enrich data before it is loaded into the data lake, ensuring that the data is accurate, complete and consistent. The data lake can then be used to store and process the data, making it available for advanced analytics and machine learning tasks.
With the integration of master data management and data lake, organizations can achieve a single version of truth, where data is accurate, consistent and complete, while also having the ability to store and process large amounts of data in a flexible and cost-effective way.
EXPLORE
Multidomain Master Data Management