Des données « propres » ne sont pas synonymes de données sur lesquelles votre IA peut s'appuyer pour raisonner. La plupart des entreprises disposent des premières. Très peu possèdent les secondes.
Vos systèmes d’IA traitent les données au pied de la lettre. Un moteur de recommandation ne remarque pas qu’un fournisseur est inactif depuis six mois : il voit simplement un enregistrement valide et agit en conséquence. Un agent des achats ne se demande pas si un prix correspond au prix catalogue ou au coût de revient : il choisit une interprétation et s’y tient.
Les données ont passé tous les contrôles de qualité, mais des défaillances surviennent quand même. Ce qui manque, c’est une intelligence régie par des règles.
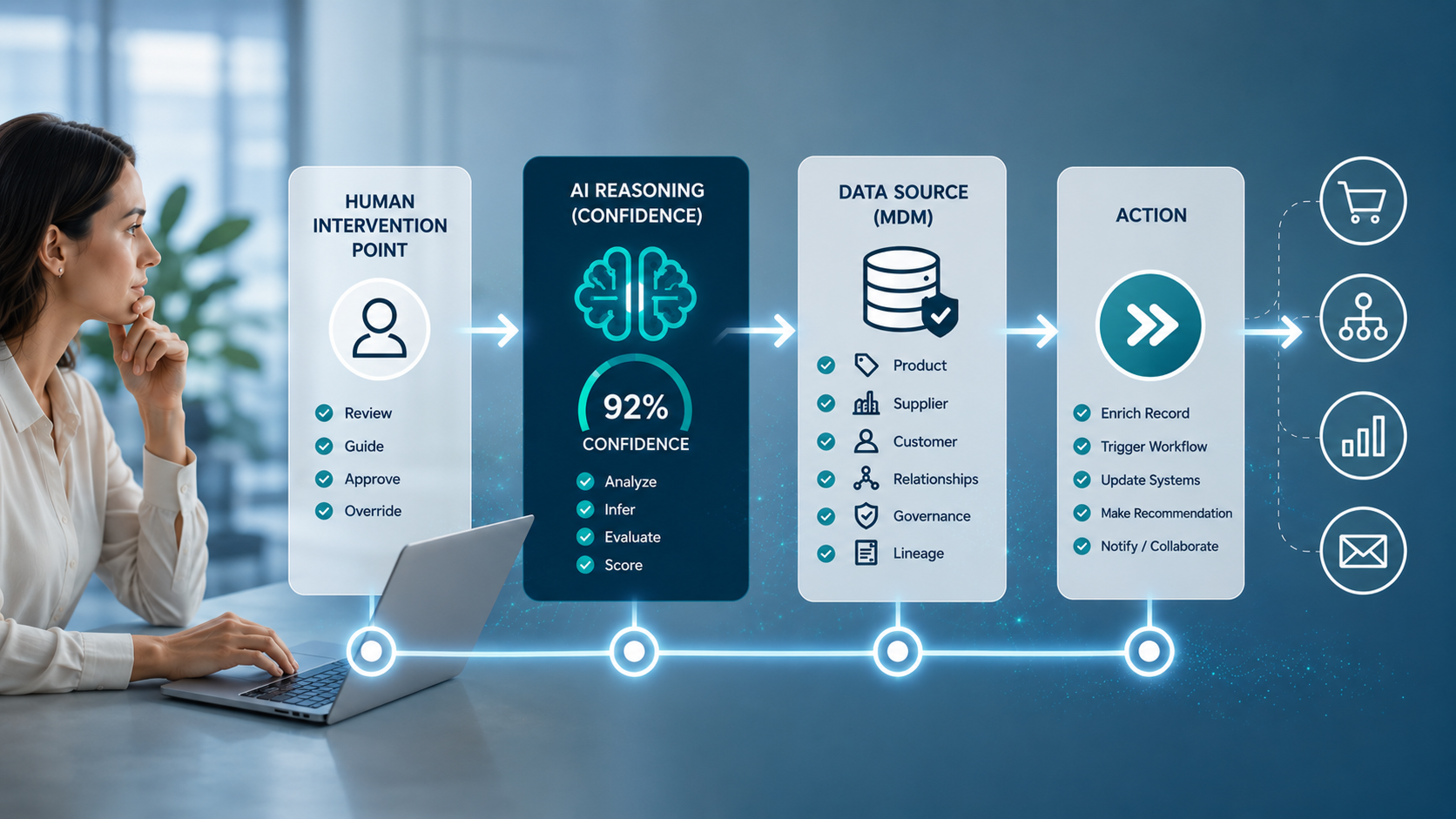
L’intelligence régie est une couche de sens qui vient se superposer à des données propres et qui indique aux systèmes d’IA non seulement quelles sont les valeurs, mais aussi :
- Ce qu’elles signifient
- Comment elles s’articulent avec tout le reste
- Quelles règles s’appliquent
Sans cela, les systèmes d’IA prennent des décisions avec certitude sur la base d’un contexte incomplet.
Il s’agit là d’une connaissance essentielle à l’ère de l’IA ; poursuivez donc votre lecture pour découvrir la différence entre les données « propres » et les données « gouvernées », et pourquoi cela revêt une importance bien plus grande que ne le pensent la plupart des organisations.
Pourquoi les données propres et les données gouvernées constituent deux problèmes distincts
Le travail sur la qualité des données résout un problème spécifique :
Tous les systèmes utilisent-ils les mêmes informations de manière cohérente ?
Cela signifie qu’il n’y a ni doublons, ni valeurs nulles, ni erreurs de formatage. L’identifiant client 12345 désigne la même personne dans les services de facturation, d’expédition et de service client.
C'est précieux. Mais cela ne répond pas à une autre question : que signifient ces données ?
Votre base de données clients peut être parfaitement propre tout en ne contenant aucune définition commune de ce qui fait qu'une personne est un client. S'agit-il d'une adresse e-mail ? D'un historique d'achats ? D'un abonnement actif ?
En l’absence de clarté, différents systèmes interprètent un même enregistrement de manière différente – et les systèmes d’IA héritent directement de cette ambiguïté.
La distinction se résume à ceci :
- La qualité des données pose la question suivante : « Cette valeur est-elle correcte et cohérente ? »
- La gouvernance des données pose la question suivante : « L’IA sait-elle ce que signifie cette valeur ? »
Ce sont des problèmes liés, mais qui nécessitent des solutions différentes. On ne peut pas parvenir à la clarté sémantique uniquement par la déduplication. La plupart des entreprises ont passé des années à optimiser le premier aspect, tout en négligeant largement le second.
C’est là que se produisent les défaillances de l’IA.
Les 4 capacités que l'intelligence régie apporte et que des données propres ne peuvent pas offrir
1. Clarté sémantique
Des données propres indiquent à vos systèmes quelles valeurs existent. La clarté sémantique leur indique ce que ces valeurs signifient dans le contexte de votre entreprise.
Une fiche produit dont le stade du cycle de vie est « en déclin » a une signification précise, par exemple « ne pas la privilégier dans les recommandations » ou « ne pas conclure de nouveaux contrats fournisseurs pour ce produit ». De même, un statut client « inactif » n’a pas la même signification dans votre système de facturation que dans votre système marketing.
La clarté sémantique rend ces définitions explicites et lisibles par machine, afin que tous les systèmes fonctionnent sur la base d’une même compréhension.
2. Gouvernance des relations
Les entités n’existent pas de manière isolée. Un produit appartient à une catégorie, provient d’un fournisseur, est assorti de mentions de conformité et se situe à un stade particulier de son cycle de vie. Un client a des commandes, des préférences, un historique de paiement et un profil régional.
La gouvernance des relations rend ces liens explicites.
Sans elle, les systèmes d’IA ne voient que des enregistrements isolés. Avec elle, ils perçoivent le contexte.
3. Règles métier exécutables
C'est là que les systèmes d'IA peuvent suivre votre logique métier. Ils ne se contentent pas de lire vos données, mais agissent dans le respect de vos contraintes.
Concrètement, cela pourrait par exemple se traduire par :
- Ne pas recommander de produits provenant de fournisseurs dont le statut est « inactif »
- Ne pas proposer de produits en dehors du territoire autorisé d’un client
- Signaler toute commande d’approvisionnement pour laquelle la note de risque du fournisseur dépasse le seuil fixé
Lorsqu’une règle est enfreinte, le système sait exactement pourquoi. Et lorsqu’une décision est prise correctement, vous pouvez retracer précisément quelles règles l’ont régie.
4. Provenance et traçabilité
Chaque valeur a un historique. D’où provient-elle ? Quand a-t-elle été mise à jour pour la dernière fois ? Dans quelle mesure pouvons-nous nous y fier ?
C'est important, car la fiabilité des décisions prises par l'IA dépend entièrement de la fiabilité des données qui les alimentent. Lorsqu'un problème survient – et cela finira par arriver –, la provenance permet de déterminer quelles données ont alimenté la décision, à quel système elles appartenaient et où se situait la faille.
C’est ce qui transforme une correction ponctuelle en une amélioration durable.
À quoi ressemble une intelligence régulée lorsqu’elle est correctement mise en place ?
Prenons un exemple :
- Un client consulte des fauteuils de bureau. Un moteur de recommandation trouve un produit correspondant : même catégorie, prix similaire. Une logique claire et des données fiables.
- Sans gouvernance, la recommandation est envoyée. Le produit provient d’un fournisseur avec lequel l’entreprise a cessé de travailler il y a six mois. La fiche produit est valide, tout y est correct, mais aucun indicateur ne signale qu’elle est « inactive ».
- Le client passe commande. Il attend des semaines, mais la commande n’est jamais expédiée.
Avec une gouvernance en place, la même requête se déroule différemment. Avant que la recommandation n’apparaisse, le moteur vérifie :
- Le fournisseur est-il actif ?
- Le produit est-il disponible dans la région du client ?
- Le stock disponible correspond-il à des articles prêts à être expédiés, ou s'agit-il d'articles bloqués ou endommagés ?
La réponse à la première question est non. La recommandation n'est pas envoyée.
Le bénéfice immédiat
Le bénéfice immédiat est qu’aucun échec ne se produit.
L'avantage considérable, à long terme
Le changement le plus important concerne ce qui se passe lorsqu’un problème survient. Sans gouvernance, l’équipe se retranche, identifie la lacune dans les données, la corrige manuellement et attend la prochaine défaillance, qui se manifestera sous une autre forme. Le même cycle de gestion de crise, à l’infini.
Avec une gouvernance en place, une décision erronée met en évidence une lacune spécifique. Le statut du fournisseur n'était pas à jour.
- Corrigez-la de manière systématique
- Ajoutez une règle qui effectue une vérification avant chaque recommandation
- Surveiller les écarts
L'IA gagne en fiabilité au fil du temps, non pas parce que l'algorithme a changé, mais parce que la gouvernance s'est améliorée.
Comment Stibo Systems vous aide à y parvenir
L’intelligence gouvernée est une capacité qui doit être mise en place de manière réfléchie à l’échelle de l’ensemble de votre infrastructure de données. STEP, notre plateforme d’intelligence de confiance, est conçue précisément pour cela.
- Les données contrôlées sur les produits et les fournisseurs empêchent les relations inactives d’apparaître dans les recommandations de l’IA avant que cela ne cause le moindre préjudice
- Les données de référence sémantiques sur les produits associent les restrictions territoriales, l’état des stocks et le contexte tarifaire à chaque enregistrement consulté par les agents
- Une vue à 360° du client régulée évite que des définitions contradictoires des statuts « actif », « inactif » et « à risque » ne sèment la confusion chez vos agents en contact avec la clientèle
- Les données de référence fournisseurs, soumises à des règles strictes, excluent les fournisseurs à haut risque ou non conformes des décisions d’approvisionnement autonomes
- La traçabilité complète des données et des règles permet à votre équipe d’expliquer précisément quelles données et quelles règles ont motivé chaque décision prise par l’IA
- Une base de données régie évite que chaque nouvelle initiative d’IA ne parte de zéro – ce qui réduit les délais de mise en production à chaque déploiement
- Une intelligence cohérente à travers les applications, les workflows et les agents empêche votre entreprise de prendre des décisions différentes à partir des mêmes données
Si vos projets d’IA piétinent en production, le problème réside rarement dans l’algorithme. Commencez par examiner les données sur lesquelles il se base.