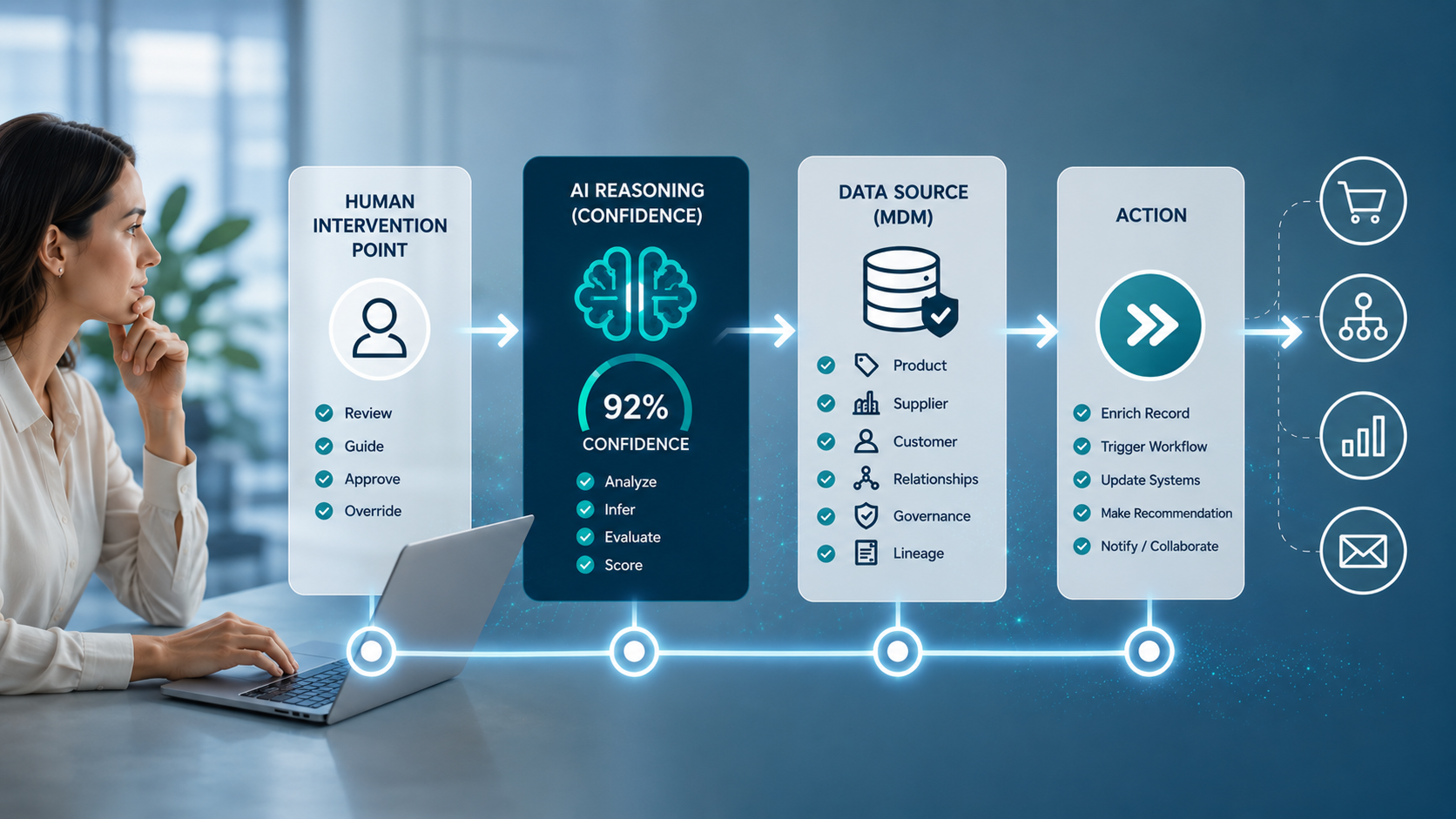
Vos clients demandent à l'IA de trouver des produits comme les vôtres. Mais lorsque l'IA ne trouve pas de données fiables sur les produits, elle recommande plutôt vos concurrents - ou vous ignore complètement.
Les systèmes d'IA évaluent si les informations sur vos produits sont complètes, cohérentes et exactes avant de décider de vous recommander.
La plupart des marques n'ont pas mis à jour leur infrastructure de données pour faire face à cette réalité. C'est donc le moment idéal pour prendre la tête de votre secteur.
La différence entre être recommandé et être invisible se résume à cinq problèmes de données spécifiques que vous rencontrez probablement en ce moment.
Dans cet article de blog, je vais vous présenter ces cinq problèmes, vous expliquer pourquoi il est important de les résoudre pour votre chiffre d'affaires et, bien sûr, comment les résoudre.
Mais d'abord, il faut planter le décor.
Vos clients externalisent une grande partie des décisions
Lorsque les clients utilisaient les moteurs de recherche, ils effectuaient le filtrage.
-
Ils comparaient les options
-
Ils lisaient les avis
-
visitaient des sites web...
Ils prenaient eux-mêmes la décision. Il vous suffisait d'apparaître dans les résultats.
Avec l'IA, vos clients confient leur décision à une machine. Ils sont de plus en plus nombreux à demander : "Quel est le meilleur haut-parleur sans fil à moins de 200 euros ?
"Quel est le meilleur haut-parleur sans fil à moins de 200 euros ?" et acceptent les recommandations de l'IA. Ils n'approfondissent pas leur recherche. Et ils ne visitent pas votre site si l'IA ne le leur suggère pas d'abord.
L'IA assume la responsabilité. Vos données doivent donc convaincre la machine, et non la personne.
Et les machines évaluent les données différemment des personnes. Elles ne s'intéressent pas aux textes persuasifs. Elles s'intéressent à l'exhaustivité, à la cohérence, à l'exactitude - des qualités qui témoignent de la fiabilité des données.
Lorsque vous êtes en concurrence pour attirer l'attention d'un être humain, c'est votre meilleur produit qui l'emporte. Lorsque vous êtes en concurrence pour obtenir des recommandations de l'IA, ce sont vos meilleures données qui l'emportent.
La gouvernance des données relevait auparavant du back-office. Aujourd'hui, elle a un impact sur le chiffre d'affaires.
La gouvernance des données a vécu dans l'informatique. Listes de contrôle de conformité. Des règles de qualité des données. Personne dans les ventes ne s'en souciait parce que cela n'affectait pas la visibilité ou le trafic.
Les moteurs de recherche n'exigeaient pas des données parfaites - ils se contentaient d'indexer ce qui existait.
Les systèmes d'IA exigent une approche différente. Ils privilégient les sources dont les données sont incomplètes ou incohérentes. La mauvaise qualité n'est pas une bonne chose. Mais désormais, elle vous coûte également des recommandations. Découverte. Des revenus réels.
Les 5 problèmes de données qui empêchent l'IA de vous recommander
1. Des données incomplètes signifient que l'IA ne peut pas vous recommander en toute confiance
Les spécifications de votre produit présentent des lacunes. Des attributs essentiels manquent - des dimensions que vous n'avez pas saisies, des détails de compatibilité que vous n'avez jamais documentés, des mesures de performance que vous considériez comme évidentes...
Lorsque l'IA évalue votre produit par rapport à ses concurrents, elle y prête vraiment attention.
Les données incomplètes sont un signe d'incertitude. Les systèmes d'IA excluent des comparaisons les produits pour lesquels il manque des informations, car ils ne peuvent pas les évaluer en toute confiance par rapport à d'autres solutions. Si vous ne figurez pas dans la comparaison, vous ne serez pas recommandé.
Le contenu n'y changera rien. Un meilleur texte marketing ne comble pas les lacunes en matière de données. Seule une information complète sur le produit peut le faire.
2. Des données incohérentes d'un canal à l'autre font douter l'IA de votre marque
Le même produit est décrit différemment sur votre site web, vos listes de places de marché et vos sites régionaux.
-
Un canal indique la largeur × la profondeur × la hauteur en pouces, un autre en centimètres - et les conversions ne sont pas alignées.
-
Votre site web indique "100 % polyester", mais la liste de votre partenaire commercial mentionne "mélange de polyester" sans préciser les pourcentages.
-
Votre plateforme de commerce électronique indique "en stock", alors que la liste de votre place de marché indique "disponibilité limitée" ou "pré-commande".
L'incohérence est un signe de manque de fiabilité. Les systèmes hiérarchisent activement les sources auxquelles ils ne font pas confiance, ce qui signifie que vos produits sont relégués au second plan dans les recommandations. Ou encore exclus.
Le client et l'IA sont d'accord sur ce point : Comment faire confiance à une marque lorsque ses propres données se contredisent ?
3. Sans contexte sémantique, l'IA ne peut pas expliquer pourquoi votre produit est le meilleur choix
Vous avez les spécifications. Poids, dimensions, certifications, matériaux...
Mais vous n' avez pas les relations et le contexte qui expliquent :
-
quand utiliser votre produit
-
Quels sont les problèmes qu'il résout
-
Quels sont les secteurs d'activité qui en bénéficient le plus
-
pourquoi un client devrait vous choisir plutôt qu'une autre solution. L'IA peut réciter des spécifications. Mais elle ne peut pas expliquer pourquoi sans contexte.
Si le cas d'utilisation n'est pas clair, vos produits deviennent interchangeables. Une option parmi d'autres avec des spécifications similaires.
L'IA n'a aucune raison de vous recommander spécifiquement.
La richesse sémantique - les connexions entre les données qui créent du sens - distingue les produits différenciés des produits de base. Sans elle, même votre produit supérieur semble générique aux yeux des systèmes d'IA.
4. L'IA évite activement les sources de données de mauvaise qualité
Les problèmes de qualité des données s'accumulent. Les fautes de frappe dans les noms de produits, les spécifications obsolètes, les entrées en double et les lacunes en matière de validation permettent aux clients et aux systèmes d'IA de détecter des erreurs élémentaires.
De plus, les systèmes d'IA privilégient activement les sources contenant des informations incohérentes et sujettes aux erreurs.
En effet, une qualité médiocre est synonyme de manque de fiabilité. Selon le raisonnement de l'IA, si vos données comportent des erreurs, d'autres aspects de la fiabilité de votre marque sont remis en question.
Vos concurrents dont les données sont plus propres sont mieux placés dans les recommandations. Vous êtes filtré.
5. Lorsque vous mettez trop de temps à enrichir de nouveaux produits, l'IA passe à autre chose
Les nouveaux produits sont incomplets dans votre système.
-
Spécifications manquantes
-
Descriptions non finalisées
-
Catégorisation en attente
Le temps que vous enrichissiez les données selon des normes acceptables, l'IA a déjà indexé la version incomplète. Et elle a marqué votre marque comme étant de faible qualité sur la base de cet instantané.
Les systèmes d'IA forment des impressions à la vitesse de l'éclair.
Une fois qu'ils ont indexé des informations incomplètes ou inexactes sur vos produits, il est difficile de se remettre de cette évaluation. Les dommages s'aggravent au fil du temps, à mesure que l'IA continue de vous déprivilégier.
Ensemble, tous ces problèmes signalent à l'IA : "ne recommandez pas cette marque"
Ces échecs ne sont pas isolés. Des données incomplètes, combinées à un manque de richesse contextuelle, combinées à une qualité médiocre sur l'ensemble des canaux, créent un message cumulatif pour les systèmes d'IA : "Peu fiable, indigne de confiance, ne vaut pas la peine d'être recommandé".
L'IA n'évalue pas les problèmes un par un. Elle agrège les signaux.
Spécifications manquantes + informations contradictoires + fautes de frappe = une marque qui ne mérite pas d'être visible. Chaque problème renforce les autres, ce qui aggrave votre profil de données global.
Une lacune dans les données peut être corrigée. Cinq problèmes systémiques sont un verdict.
Comment préparer vos données produit pour l'IA
Pour des données prêtes pour l'IA, vous avez besoin d'une gouvernance cohérente sur l'ensemble de vos canaux et systèmes. Une seule source de vérité pour les informations sur les produits. Pas de fragmentation entre les sites web, les places de marché, les plateformes régionales et les bases de données internes.
La fiabilité est la base.
-
Attributs complets des produits
-
Des descriptions cohérentes partout
-
Des spécifications précises
-
Un contexte sémantique qui explique les cas d'utilisation et la différenciation
-
des règles de qualité des données qui détectent les erreurs avant qu'elles n'atteignent les clients ou les systèmes d'intelligence artificielle.
Ce n'est pas exactement quelque chose que vous superposez à votre infrastructure existante.
Vous avez besoin d'une fondation de données conçue spécifiquement pour cela. Une fondation qui assure la cohérence à l'échelle et maintient les informations sur les produits à jour sur tous les canaux où les systèmes d'IA les trouvent.
Résoudre tout cela avec Product Experience Data Cloud
Chez Stibo Systems, notre Product Experience Data Cloud centralise toutes vos informations produit dans une source de vérité gouvernée.
-
Chaque attribut est précis, complet et cohérent - et automatiquement appliqué sur tous les canaux
-
Des règles de qualité automatisées valident les données avant qu'elles n'atteignent les clients ou les systèmes d'intelligence artificielle.
-
Les attributs manquants sont signalés. Les incohérences apparaissent immédiatement. Les fautes de frappe et les informations obsolètes sont détectées avant qu'elles ne nuisent à votre signal de confiance.
La rapidité est importante. Les nouveaux produits sont enrichis plus rapidement, de sorte qu'ils sont indexés par les systèmes d'IA alors que vos données font encore autorité. Et avant que les concurrents ne comblent l'écart.
Une seule base pour tout faire fonctionner. Optimisation du moteur de réponse, personnalisation, commerce conversationnel... Vous n'avez pas besoin de construire une infrastructure de données distincte pour chaque cas d'utilisation de l'IA en aval. Vous construisez la base de données de confiance une seule fois, puis vous l'utilisez partout.
La richesse sémantique ajoute le contexte dont l'IA a besoin pour vous différencier - cas d'utilisation, relations entre les produits et scénarios d'application. Vous savez, ces informations qui transforment les spécifications en recommandations.
La suite dépend de vous
Les systèmes d'IA décident maintenant quels produits sont découverts. Vous ne pouvez rien y changer, mais vous pouvez décider si votre infrastructure de données est prête pour cela.
Chaque jour où vos données ne sont pas prêtes pour l'IA vous coûte des découvertes.
Vos concurrents qui ont corrigé leur base de données sont recommandés. Vous vous faites filtrer. Plus vous attendez, plus il vous sera difficile de vous remettre de l'évaluation de votre marque par l'IA.
Dans cet article de blog, j'ai décrit cinq problèmes liés aux données :
-
Spécifications incomplètes
-
Manque de cohérence
-
Contexte manquant
-
Mauvaise qualité
-
Enrichissement lent
Ces problèmes sont tous très répandus. La plupart des marques les ont tous les cinq. Mais il est possible de les résoudre en adoptant une infrastructure et une approche de gouvernance adéquates.
L'optimisation des moteurs de réponse n'est pas un nouveau canal à gérer, c'est plutôt une conséquence de la façon dont vous gérez vos données. Les cinq problèmes évoqués dans ce billet constituent l'état par défaut de la plupart des marques, et les systèmes d'IA les pénalisent déjà pour cela. La bonne nouvelle, c'est que pour les résoudre, il n'est pas nécessaire de mettre en place une stratégie OEA distincte. Elle nécessite la même chose que tous les cas d'utilisation de l'IA : une source de vérité unique et régie pour les informations sur vos produits.
Les marques qui apparaissent régulièrement dans les recommandations générées par l'IA partagent une chose : des données produit que les systèmes d'IA peuvent évaluer en toute confiance. Product Experience Data Cloud offre cette capacité à l'échelle dont votre marque a besoin.
FAQ
Comment puis-je savoir si les données de mon produit présentent les cinq problèmes que vous avez mentionnés ?
Commencez par vos catégories de produits les plus importantes. Ouvrez un outil d'IA comme ChatGPT, Perplexity ou Gemini et recherchez des recommandations de produits dans votre catégorie. Si votre marque n'apparaît pas, il est très probable que vos données soient déjà filtrées. Ensuite, vérifiez si le même produit est décrit de manière identique sur votre site web, vos annonces sur les marketplaces et vos sites régionaux. Recherchez les spécifications manquantes que les concurrents ont. Chronométrez le temps nécessaire pour créer un nouveau produit, de l'intégration initiale à la pleine disponibilité sur le marché. Ces audits révèlent quels problèmes sont les plus graves.
La centralisation des données améliore-t-elle vraiment les recommandations de l'IA, ou n'est-ce qu'une bonne pratique ?
Cela améliore directement les recommandations. Les systèmes d'IA sont plus susceptibles de citer et de recommander des marques avec des données centralisées et gouvernées, car la cohérence et l'exhaustivité signalent la fiabilité. Les marques qui agissent en premier avec une infrastructure de données propre constatent des améliorations mesurables dans les mentions d'IA en quelques mois.
Quelle est la différence entre corriger la qualité des données et construire une base prête pour l'IA ?
La qualité des données corrige les erreurs individuelles – en attrapant les fautes de frappe, en validant les spécifications. Une base prête pour l'IA prévient systématiquement les problèmes. Il impose la cohérence entre les canaux avant que les données ne soient mises en ligne, automatise la validation de la qualité et ajoute le contexte sémantique dont l'IA a besoin pour vous différencier. L'un est réactif ; l'autre est préventif à grande échelle.
Combien de données produit ai-je besoin pour que l'IA me recommande ?
La complétude varie selon l'industrie et le type de produit, mais les systèmes d'IA ont besoin de suffisamment d'attributs pour évaluer vos produits par rapport aux alternatives de manière fiable. Le seuil exact dépend de votre catégorie, mais le schéma est constant : plus les données sont complètes = plus la probabilité de recommandation est élevée.
Si je corrige mes données, combien de temps avant que les systèmes d'IA ne s'en aperçoivent ?
Les systèmes d'IA réindexent et réévaluent continuellement les sources. Les améliorations de la qualité des données peuvent modifier le comportement de l'IA en quelques semaines, bien que cela dépende de la fréquence à laquelle les systèmes explorent vos sources de données. Les premières améliorations des signaux de fiabilité s'accumulent avec le temps.
Puis-je faire cela sans remplacer l'ensemble de mon infrastructure de données ?
Pas tout à fait. Vous avez besoin d'une couche de gouvernance centralisée qui puisse imposer la cohérence à travers vos systèmes et canaux existants. Un remplacement complet n'est pas nécessaire, mais vous avez besoin d'une infrastructure conçue spécifiquement pour la gouvernance des données multi-canaux – pas de rustines sur des systèmes fragmentés.