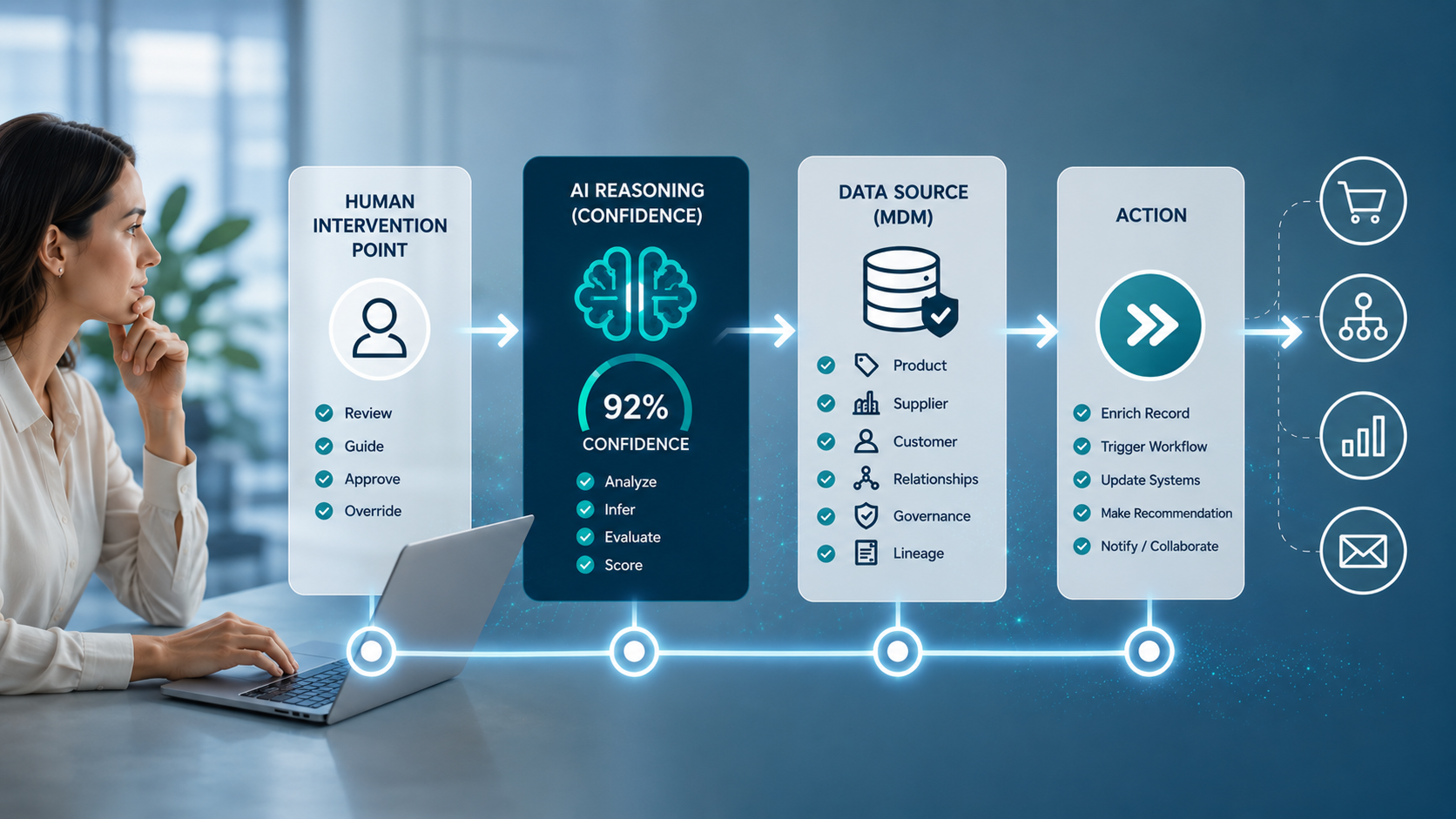
Les données synthétiques sont des données de test. Elles fluidifient le fonctionnement de l’entreprise. Si elles sont automatisées avec l’IA ou le machine learning, le Master Data Management (MDM) devient indispensable pour garantir des décisions non biaisées.
Les données génèrent des données qui, à leur tour, génèrent d’autres données. Comment savoir si ce qui est produit est adapté à l’objectif ? Un robot est conçu, par exemple, pour nous aider à prendre une décision d’investissement avisée ou simplement pour fournir la meilleure réponse à une question du service client... Mais que se passe-t-il si ce robot se trompe ?
À l’évidence, il est important de tester toutes les possibilités des solutions. L’IA domine de plus en plus dans l’automatisation des processus décisionnels. Il est donc vital de s’assurer que les opérations de machine learning, rendues possibles par le MDM, fonctionnent à partir de données de haute qualité. Ces données doivent être explicables, dignes de confiance et exemptes de biais.

Avant que les données ne deviennent opérationnelles, elles doivent souvent être organisées en ensembles de données pour répondre à différentes exigences en matière de tests et de modélisation. Il est en effet nécessaire de déterminer comment les applications, les modèles d’analyse et les processus basés sur l’IA se comporteront par rapport à ces ensembles de données. Les données concernées peuvent être des données réelles, représentatives ou expérimentales. C’est là qu’interviennent les données synthétiques.
Qu’est-ce que les données synthétiques et pourquoi sont-elles de plus en plus importantes ?
Les données synthétiques sont générées de manière algorithmique pour compenser les déficiences des données réelles. Elles répondent à des besoins face auxquels les données réelles peuvent s’avérer insuffisantes. Dans de nombreux cas, les données synthétiques tirent une grande partie de leur contenu des données de production. Elles sont souvent fidèles à la nature statistique des données source sans en être une copie exacte. Au-delà de données représentatives du monde réel, les données synthétiques peuvent également inclure des ensembles de données qui génèrent des « pistes » à tester. Les tests peuvent par exemple concerner le comportement d’un système sous certaines conditions. De tels ensembles de données facilitent l’analyse prédictive.
De toute évidence, pour pouvoir fournir des résultats utiles, les données synthétiques doivent bénéficier du même niveau de confiance que les données opérationnelles. Pour pouvoir être utilisées avec des applications d’IA, ces données synthétiques doivent également être explicables et exemptes de biais. C’est pourquoi il est vital de commencer par obtenir des données opérationnelles, ou de production, correctes. Elles serviront de point de départ pour la génération des données synthétiques. Il est également important de veiller à ce que les cas d’usage que l’on ne trouve pas normalement dans les données de production puissent être assemblés et organisés. À cette fin, le Master Data Management peut être utile.
Qu’est-ce que le Master Data Management (MDM) ?
Lorsque nous pensons aux données de référence, nous pensons surtout aux données opérationnelles :
- Données de référence client utilisées pour les opérations de vente et de service
Données de référence produit collectées auprès des fournisseurs lors des processus d'approvisionnement
Données de référence sur les actifs nécessaires pour modéliser les infrastructures opérationnelles essentielles
Le MDM est un outil essentiel pour fournir une vue unique et fiable sur des informations stratégiques telles que les données client. Avec des données de référence fiables, vous réduisez le coût d’intégration des applications, vous améliorez l’expérience client et vous disposez d’informations exploitables issues de l’analyse.
Il est indispensable de disposer d’une vision transparente de ces données de référence pour pouvoir les rendre à la fois fiables et significatives. La transparence découle de la signification des données, de leur finalité et de la politique de gouvernance qui les définit.
Le MDM définit et met en œuvre des politiques de gouvernance pour garantir la présence de qualités importantes pour les données de référence. Ces qualités incluent l’origine, l’exactitude, la cohérence, l’accessibilité, la sécurité, l’auditabilité et l’éthique. Elles sont supervisées et mesurées par rapport aux objectifs métier.
Le Master Data Management peut vous aider à gouverner vos ensembles de données pour en assurer une représentation plus fiable et plus complète lorsqu'ils sont générés sous forme d'ensembles de données synthétiques. Avec de bons ensembles de données synthétiques, les projets de data science produisent de meilleurs résultats en matière de prévisions et de machine learning.
Les données synthétiques pour l’IA et le machine learning
La gestion des données synthétiques est fondamentale pour l’IA et le machine learning. La formation des modèles de machine learning exige des données. Les données synthétiques peuvent fournir le volume et les cas d’usage nécessaires au machine learning. Le Master Data Management contribue à la génération de données non biaisées. Cela favorise une meilleure vérification par l’IA qui exploite ces bonnes données. Il en découle des résultats plus fiables [qui facilitent la prise de décision].
Utilisation des données synthétiques dans le retail
Imaginons le lancement d'un nouveau produit. Quel effet son placement aura-t-il sur les ventes ? Quels segments client sont les plus susceptibles de l’acheter ?
Tester l’introduction d’un produit du point de vue de la data science, exige d’avoir accès à de bonnes données représentatives en masse. Tout commence par l’inclusion des données client et produit existantes. L’exactitude et la visibilité de ces données sont essentielles. Il importe de les mesurer et de les corriger avant toute analyse. Le MDM peut vous y aider.
Le MDM prend en charge et sécurise la bonne mise en œuvre d’une politique pour les données client, ce qui inclut les responsabilités et les critères d’exhaustivité et de qualité. Le retailer n’a pas nécessairement besoin d’une vue complète à 360° du client. Il a simplement besoin d’une vue adaptée à son objectif spécifique : créer les ensembles de données synthétiques qui confirment les prévisions relatives au potentiel de vente du nouveau produit.
Si les données du monde réel ne sont pas suffisamment détaillées et nombreuses pour générer des données permettant de tester davantage de possibilités et de chemins de décision, le MDM peut aider. Il peut gérer des ensembles de données client anonymes offrant une meilleure qualité.
Ayant aligné les règles de données dans le MDM avec les objectifs du projet de data science ou de machine learning, le retailer peut maintenant développer des ensembles de données synthétiques appropriés pour les analyses prédictives ultérieures.
L’IA et le machine learning deviennent des éléments omniprésents de l’expérience client, aidant les consommateurs à faire des choix éclairés. Le consommateur peut par exemple créer une liste des produits qu’il a consultés. Les algorithmes de machine learning examinent les attributs de ces produits et peuvent alors proposer des produits et des services complémentaires en tenant compte du comportement de ce consommateur.
Utilisation des données synthétiques dans les services financiers
Le secteur des services financiers compte un nombre important de cas d’usage clés pour la gestion des données synthétiques. Par exemple, les données bancaires ou d’assurance peuvent contenir des attributs personnellement identifiables très sensibles. Or les entreprises de services financiers doivent communiquer des informations à leurs partenaires commerciaux et aux autorités de réglementation. La génération d’ensembles de données synthétiques peut les aider à supprimer les informations personnelles. Cette opération, également appelée « masquage des données », préserve les relations complexes entre les données. Pour former un algorithme destiné à détecter les fraudes, vous n’avez pas vraiment besoin du nom de la personne concernée. Vous devez par contre être capable de reconnaître un modèle statistique indiquant une activité suspecte.
Lors de l’analyse des tendances historiques, si l’on veut éviter les erreurs du passé, il est nécessaire de générer des ensembles de données synthétiques qui représentent à la fois des événements réels et des scénarios de simulation. Pour les prévisions, les ensembles de données doivent refléter le passage des tendances actuelles aux tendances futures, une approche vitale pour imaginer votre prochain produit ou service.
Le MDM apporte la gouvernance aux données synthétiques, ce qui rend les résultats explicables
Avec le MDM, les ensembles de données de production originaux peuvent produire des ensembles de données synthétiques représentatifs et utiles. Parfois, le MDM peut être nécessaire pour gérer certains éléments de ces ensembles de données synthétiques afin que le machine learning puisse les traiter. Des techniques telles que le masquage des données et la production de données synthétiques peuvent être utilisées pour transformer des attributs individuels (de nombreux outils existent pour réaliser ces tâches). Les politiques de gouvernance du MDM contribuent toutefois à garantir une représentation honnête des sources originales.
Le MDM améliore la pertinence et l’explicabilité des données synthétiques en mettant en place un processus garantissant une organisation représentative, cohérente, de haute qualité et significative des informations synthétiques ou des informations d’origine. Cette approche rend l’IA plus explicable, induit moins de biais et produit des résultats plus fiables.
Pour en savoir plus sur l’importance du Master Data Management pour l’IA et le machine learning, lisez le document suivant Faites progresser votre projet d’IA avec le Master Data Management ou visitez stibosystems.com/fr.