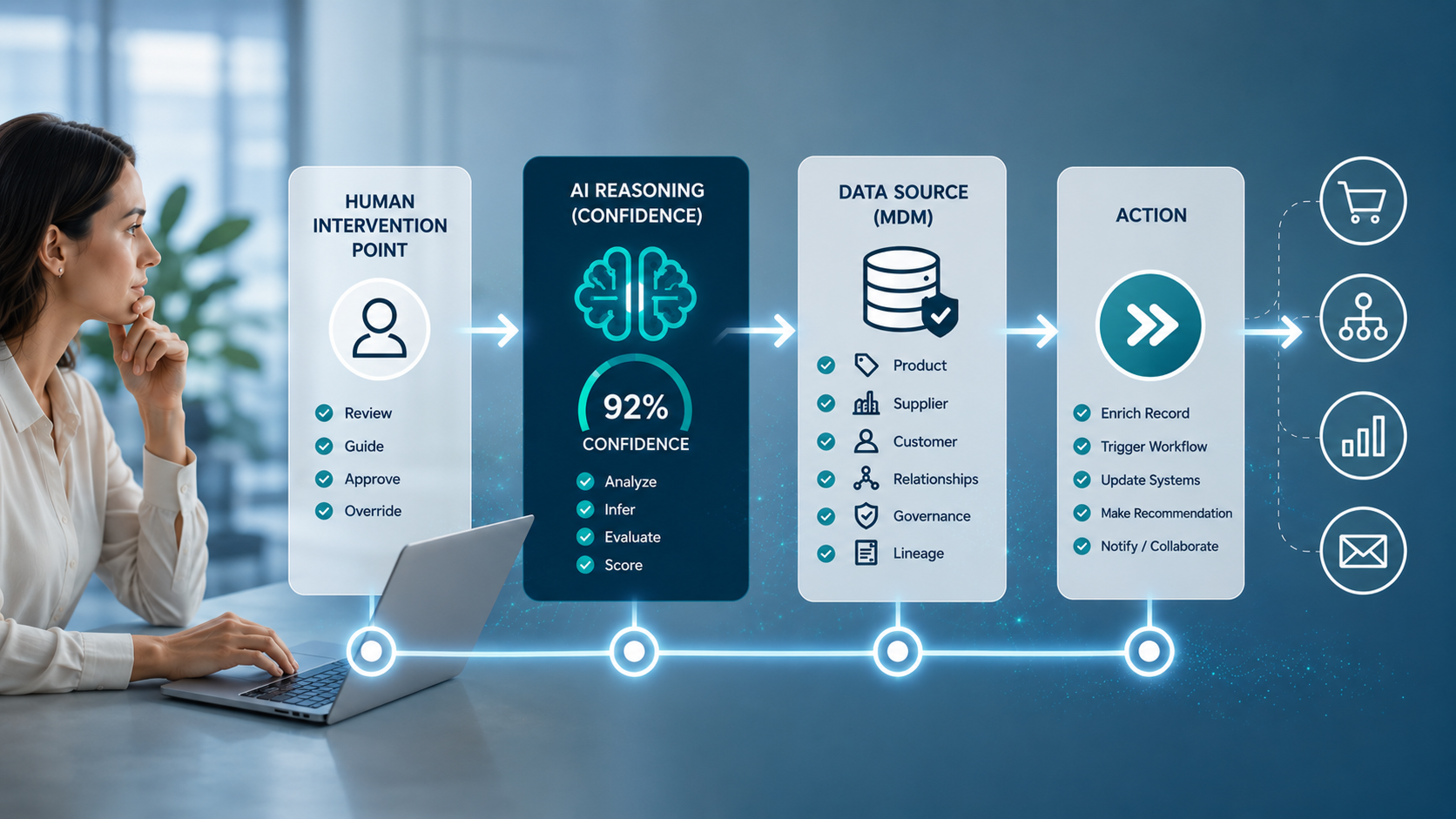
貴社の顧客は、AIに貴社のような製品を探すよう求めています。しかし、AIが信頼できる製品データを見つけられない場合、代わりに競合他社を推薦したり、あるいは完全にスキップしたりします。
AIシステムは、御社を推薦するかどうかを決定する前に、御社の製品情報が完全で、一貫性があり、正確かどうかを評価します。
ほとんどのブランドは、この現実に備えてデータインフラを更新していない。今こそ、業界をリードする絶好のチャンスなのだ。
推薦されるかされないかの分かれ目は、あなたが今抱えているであろう5つの具体的なデータの問題に行き着く。
このブログ記事で、私は5つすべてを説明し、なぜそれらを修正することがあなたの収入に重要なのか、そしてもちろん、それらを修正する方法を説明します。
その前に、まずは状況を整理する必要がある。
顧客は多くの決定をアウトソーシングしている
検索エンジンを使っていたとき、顧客はフィルタリングを行っていた。
-
選択肢を比較する
-
レビューを読む
-
ウェブサイトを訪問
顧客自身が決断を下していたのです。あなたは検索結果に表示されるだけでよかったのです。
AIを使えば、顧客は決断を機械に委ねることができます。顧客はますますこう尋ねるようになる:
「と尋ね、AIが勧めるものを受け入れる。と尋ね、AIが推奨するものを受け入れる。そして、AIが最初に提案しない限り、あなたのサイトを訪れることはない。
AIが責任を負う。つまり、あなたのデータは人ではなく機械を説得しなければならないのです。
そして、機械は人間とは異なる方法でデータを評価する。彼らは説得力のあるコピーなど気にしない。彼らが気にするのは、完全性、一貫性、正確性、つまり信頼性を叫ぶ資質である。
人間の注意を引くためには、最高の製品が勝つ。AIによる推薦を競うときは、最高のデータが勝つ。
データガバナンスは、かつてはバックオフィス的なものだった。今やそれは収益に影響を与える。
データガバナンスはIT部門に存在していた。コンプライアンスのチェックリスト。データ品質ルール。可視性やトラフィックに影響しないため、営業部門は誰も気にしなかった。
検索エンジンは完璧なデータを求めず、存在するものは何でもインデックスしていた。
AIシステムは異なるアプローチを要求する。不完全なデータや一貫性のないデータは優先順位を下げる。品質が悪いと悪い印象を与える。しかし今、それはレコメンデーションのコストにもなっている。発見。本当の収益。
AIによる推薦を妨げる5つのデータ問題
1.不完全なデータは、AIが自信を持って推薦できないことを意味する。
製品仕様にはギャップがあります。重要な属性が欠落しています - 取得していない寸法、文書化していない互換性の詳細、明らかだと思い込んでいた性能指標...。
AIがあなたの製品を競合他社と比較評価するとき、AIは本当に注意を払います。
不完全なデータは不確実性を示します。AIシステムは、情報が欠落している製品を比較対象から除外します。比較対象から外れると、推奨されなくなるからです。
コンテンツはこれを解決しない。より良いマーケティング・コピーは、データのギャップを埋めません。完全な製品情報だけがそうなのです。
2.チャネル間で一貫性のないデータは、AIにブランドを疑わせる
同じ商品でも、ウェブサイト、マーケットプレイス、地域サイトによって表記が異なります。
-
あるチャネルでは幅×奥行き×高さがインチで表示され、別のチャネルではセンチメートルで表示される。
-
御社のウェブサイトでは「ポリエステル100%」と表示されていますが、小売パートナーのリストでは「ポリエステル混紡」と表示され、比率は明記されていません。
-
eコマース・プラットフォームでは「在庫あり」と表示されているのに、マーケットプレイスでは「在庫限り」または「予約注文」と表示されている。
一貫性がないということは、信頼性に欠けるということだ。そしてシステムは、信頼できない情報源を積極的に優先順位を下げる。つまり、あなたの商品は推奨される商品から外れてしまうのだ。
この点については、顧客とAIは同意するだろう:ブランド自身のデータが矛盾しているのに、どうしてそのブランドを信頼できるのだろうか?
3.意味的な文脈がなければ、AIはあなたの製品が最良の選択である理由を説明できない。
あなたはスペックを持っている。重量、寸法、認証、素材...。
しかし、あなたが持っていないのは、説明する関係性と文脈です:
-
製品をいつ使うべきか
-
どのような問題を解決するのか
-
どの業界が最も恩恵を受けるか
-
顧客が他の製品ではなく貴社を選ぶ理由AIはスペックを説明することはできる。しかし、文脈なしにその理由を説明することはできない。
ユースケースが明確でなければ、御社の製品は交換可能なものとなってしまいます。似たようなスペックの別の選択肢に過ぎない。
AIが貴社を特別に推薦する理由はない。
セマンティックの豊かさ-意味を生み出すデータ間のつながり-は、差別化された製品をコモディティから切り離します。それがなければ、優れた製品であってもAIシステムには一般的なものに見えてしまう。
4.AIは質の低いデータソースを積極的に避ける
データ品質の問題は複合的だ。製品名の誤字、古い仕様、重複入力、基本的なミスを顧客やAIシステムに漏らす検証ギャップなどである。
そしてAIシステムは、一貫性がなく、エラーが起こりやすい情報源を積極的に優先順位を下げる。
低品質は信頼できないものと相関するからだ。AIの理屈では、データに誤りがあれば、ブランドの信頼性の他の側面が疑われることになる。
よりクリーンなデータを持つ競合他社は、レコメンデーションで上位に表示される。あなたは除外される。
5.新商品を充実させるのに時間がかかりすぎると、AIは先に進む。
新商品は不完全なままシステムに置かれる。
-
スペック不足
-
説明が確定していない
-
分類が保留されている
あなたが許容できる基準までデータを充実させた頃には、AIはすでに不完全なバージョンをインデックス化しています。そして、そのスナップショットに基づいて、あなたのブランドを低品質とマークしている。
AIシステムは光速で印象を形成する。
そして、一度あなたの商品に関する不完全または不正確な情報をインデックスしてしまうと、その評価から回復するのは難しい。AIが貴社の優先順位を下げ続けるにつれて、ダメージは時間の経過とともに拡大していく。
これらの問題はすべて一緒になって、AIに「このブランドを推薦するな」というシグナルを送る。
これらの失敗は単独では存在しない。不完全なデータ、コンテクストの豊かさの欠如、チャネル間の質の低さが組み合わさることで、AIシステムへの累積的なメッセージが生み出される:「信頼できない、信用できない、薦める価値がない。
AIは問題を一つずつ評価するわけではない。シグナルを集約するのだ。
スペック不足+矛盾する情報+誤字脱字=知名度に値しないブランド。 それぞれの問題は他の問題を補強し、あなたのデータプロフィール全体を悪く見せる。
1つのデータギャップは修正可能。5つの体系的な問題は評決となる。
商品データをAIに対応させるには
AIに対応できるデータには、すべてのチャネルとシステムで一貫したガバナンスが必要です。商品情報の真実のソースは1つ。ウェブサイト、マーケットプレイス、地域プラットフォーム、社内データベースで断片化されていないこと。
信頼性が基盤です。
-
完全な商品属性
-
あらゆる場所で一貫した説明
-
正確な仕様
-
ユースケースと差別化を説明するセマンティック・コンテキスト
-
顧客やAIシステムに届く前にエラーを発見するデータ品質ルール
既存のインフラに重ねるようなものではない。
このために特別に構築されたデータ基盤が必要です。規模に応じて一貫性を確保し、AIシステムが見つけるあらゆるチャネルで製品情報を最新に保つ。
プロダクト・エクスペリエンス・データ・クラウドですべてを解決
Stibo Systemsのプロダクト・エクスペリエンス・データ・クラウドは、すべての製品情報を1つの管理された真実のソースに集約します。
-
すべての属性は正確、完全、一貫しており、すべてのチャネルで自動的に適用されます。
-
自動化された品質ルールにより、データが顧客やAIシステムに届く前に検証されます。
-
属性の欠落にフラグを立てます。矛盾はすぐに表面化します。誤字脱字や古い情報は、信頼性シグナルを損なう前に検出されます。
スピードが重要。 新製品はエンリッチメントを通過するスピードが速いため、貴社のデータがまだ信頼できるうちにAIシステムにインデックスされます。そして、競合他社がそのギャップを埋める前に。
ひとつの基盤がすべてを支える アンサーエンジン最適化、パーソナライゼーション、会話型コマース...。下流のAIユースケースごとに個別のデータ基盤を構築する必要はありません。信頼できるデータ基盤を一度構築すれば、あらゆる場所でそれを利用できる。
セマンティック・リッチネスは、AIが差別化を図るために必要なコンテキスト(ユースケース、製品間の関係、アプリケーション・シナリオ)を追加します。つまり、スペックをレコメンデーションに変える情報だ。
次に何が起こるかはあなた次第
現在、どの製品を発掘するかはAIシステムが決定している。これを変えることはできないが、自社のデータ・インフラがそれに対応しているかどうかを決めることはできる。
AIに対応したデータがない場合、1日ごとにディスカバリーのコストがかかります。
データ基盤を修正した競合他社は、推奨されるようになっている。あなたは除外される。待てば待つほど、AIによるブランド評価から回復するのは難しくなる。
このブログ記事で、私は5つのデータ問題を概説した:
-
不完全なスペック
-
矛盾
-
文脈の欠落
-
質の低さ
-
エンリッチメントの遅れ
これらはすべて広く見られる。ほとんどのブランドがこの5つをすべて抱えている。しかし、適切なインフラストラクチャーとガバナンスアプローチがあれば、これらはすべて解決可能だ。
アンサーエンジン最適化は、管理すべき新しいチャネルではなく、むしろデータの管理方法の結果なのだ。この記事にある5つの問題は、ほとんどのブランドにとってデフォルトの状態であり、AIシステムはすでにそのためにペナルティを課している。良いニュースは、これらの問題を解決するのに個別のAEO戦略は必要ないということだ。必要なのは、すべてのAIのユースケースで必要とされるものと同じである。
AIが生成するレコメンデーションに一貫して表示されるブランドには、AIシステムが自信を持って評価できる製品データという共通点があります。プロダクト・エクスペリエンス・データ・クラウドは、ブランドが必要とする規模でその能力を構築します。
よくある質問
私の製品データにあなたが言及した5つの問題があるかどうか、どうやって確認すればいいですか?
最も重要な製品カテゴリーから始めましょう。 ChatGPT、Perplexity、GeminiなどのAIツールを開いて、あなたのカテゴリーで製品の推奨を検索してください。 もしあなたのブランドが表示されない場合、データがすでにフィルタリングされている可能性が非常に高いです。 次に、同じ製品があなたのウェブサイト、マーケットプレイスのリスティング、および地域サイトで同一に説明されているか確認してください。 競合他社が持っている欠けている仕様を探してください。 新しい製品を初期のオンボーディングから市場投入までにかかる時間を測定してください。 これらの監査は、どの問題が最も深刻であるかを明らかにします。
データを集中化することで本当にAIの推奨が改善されるのか、それとも単なるベストプラクティスなのか?
それは直接的に推奨を改善します。 AIシステムは、一貫性と完全性が信頼性を示すため、管理された中央集権的なデータを持つブランドを引用し、推奨する可能性が高くなります。 クリーンなデータインフラを整備したブランドは、数ヶ月以内にAIでの言及が目に見えて改善されます。
データ品質の修正とAI対応の基盤の構築の違いは何ですか?
データ品質は個々のエラーを修正します – タイプミスを見つけ、仕様を検証します。 AI対応の基盤は、体系的に問題を防ぎます。 データが公開される前にチャネル間の一貫性を強制し、品質検証を自動化し、AIがあなたを差別化するために必要な意味的コンテキストを追加します。 一つは反応的であり、もう一つは大規模に予防的です。
AIに推薦してもらうためには、どれくらいの製品データが必要ですか?
完全性は業界や製品タイプによって異なりますが、AIシステムは代替品と比較して自信を持って評価するために十分な属性が必要です。 正確な閾値はカテゴリによって異なりますが、パターンは一貫しています:データがより完全であればあるほど、推薦される可能性が高くなります。
データを修正したら、AIシステムが気づくまでどれくらいかかりますか?
AIシステムは継続的にソースを再インデックス化し、再評価します。 データ品質の向上は、システムがデータソースをどれだけ頻繁にクロールするかによって、数週間以内にAIの挙動を変える可能性があります。 信頼性のシグナルの初期改善は、時間とともに累積します。
これを行うために、データインフラ全体を置き換えずに済むでしょうか?
完全にはそうではありません。 既存のシステムやチャネル全体で一貫性を確保できる中央集権的なガバナンスレイヤーが必要です。 完全な置き換えは必要ありませんが、マルチチャネルデータガバナンス専用に設計されたインフラが必要です。断片化されたシステムにパッチを当てるのではなく。